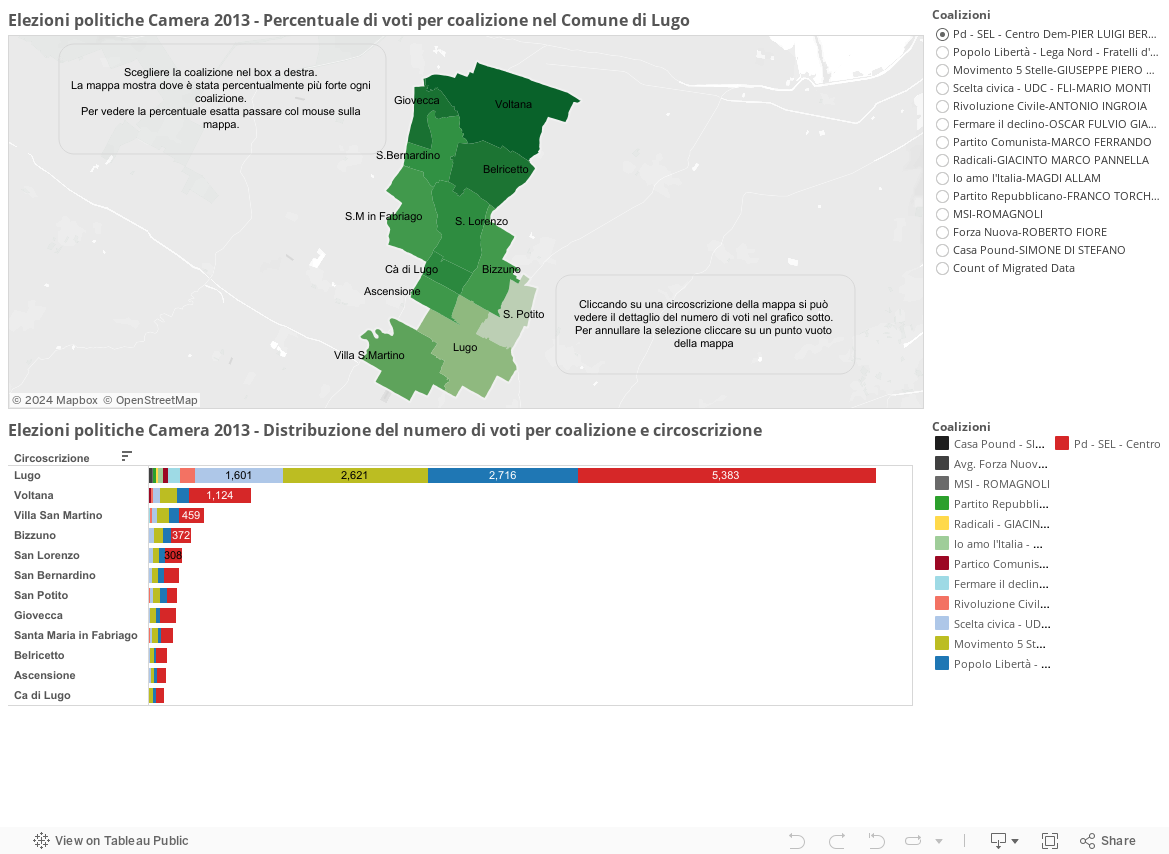
A circa una settimana dalle elezioni amministrative di Lugo ancora in molti sono indecisi su quale sindaco scegliere, con questo post vorrei dare una mano a chi come me si vuole informare in tal senso.

In questa campagna elettorale sono andati per la maggiore gli aperitivi, i pranzi di autofinanziamento, i super-ospiti, i confronti tra i candidati a colpi di slogan più che di idee; tutto molto bello per carità, e i programmi elettorali ? Si, ci sono anche quelli. Sono assai noiosi, sicuramente più noiosi di uno spritz in compagnia o di una braciolata di gruppo.
Eppure su che cosa ci si dovrebbe basare per scegliere chi ci governerà? La fiducia che ispira un candidato è sufficiente a fare una scelta? La cieca fede in una parte politica è buona consigliera? Io penso di no.
Penso che la politica sia in questo stato anche perchè le persone non leggono i programmi politici (perchè i programmi sono scritti allo stesso illeggibile modo da 50 anni....), non sanno cosa è stato pianificato per loro, se non quelle 3 o 4 proposte 'civetta' che riescono a trattenere.
Sono anche convinto che buona parte dei più accaniti sostenitori delle varie parti in campo non abbiano idea di cosa contengono i programmi dei candidati, da dove traggono tanta convinzione?
Se non si conosce cosa c'è nel programma politico di un candidato che diviene sindaco , non si può chiedere conto delle promesse non mantenute, non si può responsabilizzare la politica e la pubblica amministrazione nei 5 anni di mandato.
In quest'ultima campagna elettorale non ho visto granchè di diverso da quelle che cho visto in passato, eppure la distanza tra la politica e le persone è ormai siderale, probabilmente andava fatto qualcosa di diverso, di nuovo.
Questa lontanza tra persone e politica non si colma secondo me offrendo aperitivi o strigendo mani. Difficile chiedere razionalità ad una campagna elettorale, ma bisogna partire dalle proposte, dai programmi e dalla loro realizzazione.
Per questo ho cercato di sintetizzare le proposte dei candidati sindaco mettendole insieme per riuscire a confrontarle. Purtroppo sono riuscito a reperire con facilità in formato elettronico solo 3 programmi (Ranalli, Verlicchi, Coppola) da poter elaborare (soliti PDF che nessuno legge...), gli altri non li ho trovati e mi scuso se non ho avuto la 'voglia' anche di trascrivere papiri di carta....
Da questi 3 programmi ho cercato di estrarre le proposte, non è stato sempre facile anche perchè spesso nella prosa di questi scritti politici non si distingue bene cosa è veramente una cosa che verrà fatta o cosa invece è un intento o un tentativo o una suggestione, o anche qualcosa che verrebbe fatto comunque perchè già pianificato dall'amminitrazione in carica.
In ogni modo a colpi di copia-incolla un po' rozzi ho creato un dataset di proposte classificate con temi che mi sono sembrati accettabili. Devo dire che molte delle proposte programmatiche che ho individuato non sono facilmente misurabili in un ottica di controllo dell'operato del futuro sindaco, a mio avviso i punti di programma dovrebbero avere un qualche tipo di indicatore di performance simile a quello che si usa per verificare i Piani Esecutivi di Gestione delle amministrazioni comunali, da aggiornare durante i 5 anni di mandato.
Ho messo le proposte di programma in questa pagina nella quale si possono filtrare le proposte per tema o ancora cercare una singola parola (per esempio se qualcuno vuole sapere le sorti del Pavaglione basta che cerchi la parola in questione nell'apposito campo). Avrei potuto fare un lavoro migliore per rendere più leggibili da un punto di vista semantico le proposte (ulteriori classificazioni per esempio) ma i dati da cui partivo non me lo permettevano e anche il poco tempo a disposizione....
Embeddo anche qui di seguito ma suggerisco di usare l'apposita pagina.
In questa campagna elettorale sono andati per la maggiore gli aperitivi, i pranzi di autofinanziamento, i super-ospiti, i confronti tra i candidati a colpi di slogan più che di idee; tutto molto bello per carità, e i programmi elettorali ? Si, ci sono anche quelli. Sono assai noiosi, sicuramente più noiosi di uno spritz in compagnia o di una braciolata di gruppo.
Eppure su che cosa ci si dovrebbe basare per scegliere chi ci governerà? La fiducia che ispira un candidato è sufficiente a fare una scelta? La cieca fede in una parte politica è buona consigliera? Io penso di no.
Penso che la politica sia in questo stato anche perchè le persone non leggono i programmi politici (perchè i programmi sono scritti allo stesso illeggibile modo da 50 anni....), non sanno cosa è stato pianificato per loro, se non quelle 3 o 4 proposte 'civetta' che riescono a trattenere.
Sono anche convinto che buona parte dei più accaniti sostenitori delle varie parti in campo non abbiano idea di cosa contengono i programmi dei candidati, da dove traggono tanta convinzione?
Se non si conosce cosa c'è nel programma politico di un candidato che diviene sindaco , non si può chiedere conto delle promesse non mantenute, non si può responsabilizzare la politica e la pubblica amministrazione nei 5 anni di mandato.
In quest'ultima campagna elettorale non ho visto granchè di diverso da quelle che cho visto in passato, eppure la distanza tra la politica e le persone è ormai siderale, probabilmente andava fatto qualcosa di diverso, di nuovo.
Questa lontanza tra persone e politica non si colma secondo me offrendo aperitivi o strigendo mani. Difficile chiedere razionalità ad una campagna elettorale, ma bisogna partire dalle proposte, dai programmi e dalla loro realizzazione.
Per questo ho cercato di sintetizzare le proposte dei candidati sindaco mettendole insieme per riuscire a confrontarle. Purtroppo sono riuscito a reperire con facilità in formato elettronico solo 3 programmi (Ranalli, Verlicchi, Coppola) da poter elaborare (soliti PDF che nessuno legge...), gli altri non li ho trovati e mi scuso se non ho avuto la 'voglia' anche di trascrivere papiri di carta....
Da questi 3 programmi ho cercato di estrarre le proposte, non è stato sempre facile anche perchè spesso nella prosa di questi scritti politici non si distingue bene cosa è veramente una cosa che verrà fatta o cosa invece è un intento o un tentativo o una suggestione, o anche qualcosa che verrebbe fatto comunque perchè già pianificato dall'amminitrazione in carica.
In ogni modo a colpi di copia-incolla un po' rozzi ho creato un dataset di proposte classificate con temi che mi sono sembrati accettabili. Devo dire che molte delle proposte programmatiche che ho individuato non sono facilmente misurabili in un ottica di controllo dell'operato del futuro sindaco, a mio avviso i punti di programma dovrebbero avere un qualche tipo di indicatore di performance simile a quello che si usa per verificare i Piani Esecutivi di Gestione delle amministrazioni comunali, da aggiornare durante i 5 anni di mandato.
Ho messo le proposte di programma in questa pagina nella quale si possono filtrare le proposte per tema o ancora cercare una singola parola (per esempio se qualcuno vuole sapere le sorti del Pavaglione basta che cerchi la parola in questione nell'apposito campo). Avrei potuto fare un lavoro migliore per rendere più leggibili da un punto di vista semantico le proposte (ulteriori classificazioni per esempio) ma i dati da cui partivo non me lo permettevano e anche il poco tempo a disposizione....
Embeddo anche qui di seguito ma suggerisco di usare l'apposita pagina.